



安装NuGet包
Install-Package HtmlAgilityPack
XPath基本语法
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
爬取逻辑
我们要爬取的是百度首页的热搜榜数据
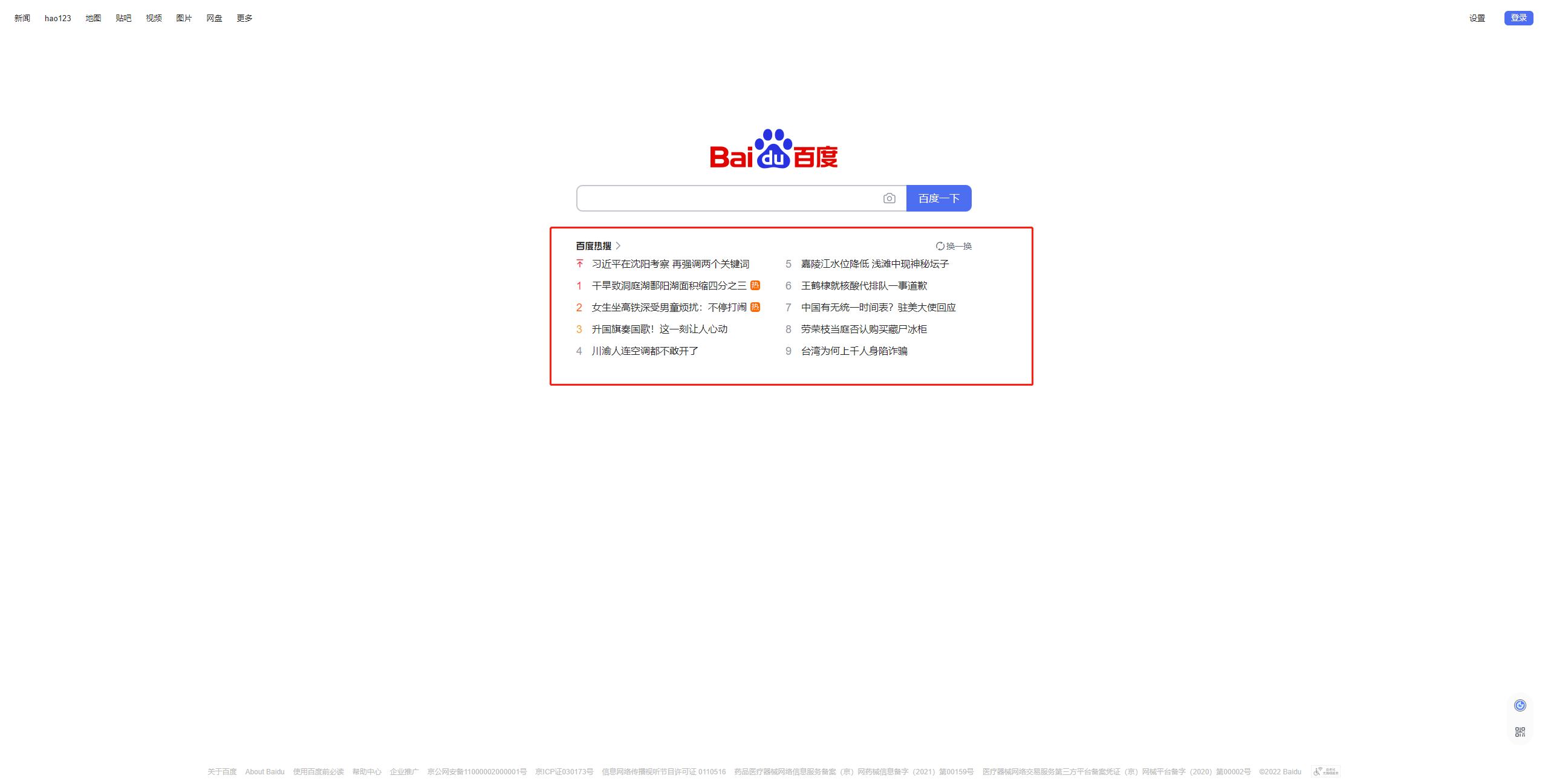
首先查看元素位置
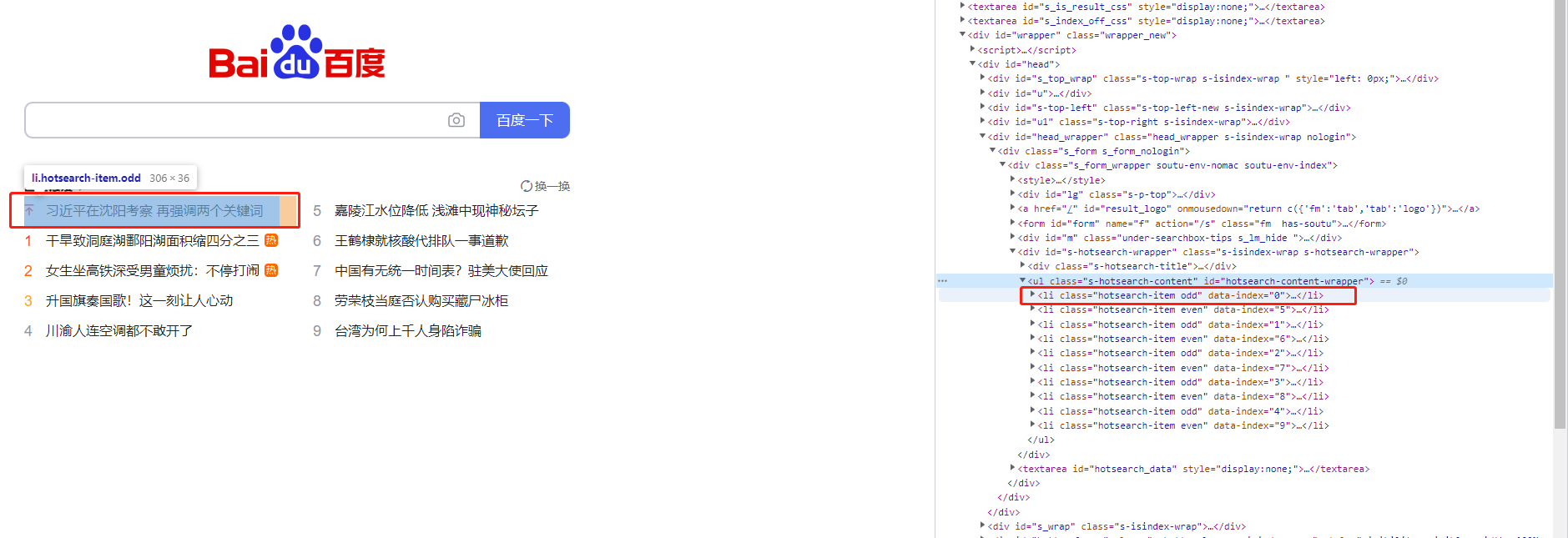
可以看到热搜数据是在这个ul标签下的每个li中存放,因此我们需要进行如下步骤:
- 通过Xpath表达式 //ul[@class=‘s-hotsearch-content’]/li 得到这个ul下的所有li
- 然后遍历所有li元素,然后通过Xpath表达式 .//span[@class=‘title-content-title’] 得到文本信息的span标签
- 获取span标签的文本值然后输出
string url = "http://www.baidu.com";
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
HtmlNode htmlNode = doc.DocumentNode;
var nodes=htmlNode.SelectNodes("//ul[@class='s-hotsearch-content']/li");
foreach (var item in nodes)
{
var temp = item.SelectSingleNode(".//span[@class='title-content-title']");
Console.WriteLine(temp.InnerText);
}
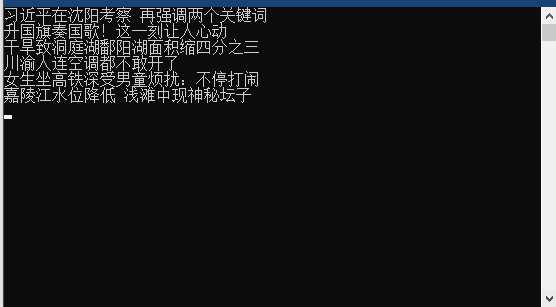
输出结果
因为有部分内容是动态渲染的所有没获取全
评论区